
我用AI做了些什么
我用AI做了些什么
在2023年的年初,我、五一和Ego一起参加了SeeDao的工作坊,和SeeDao一起实现了一个基于SeeDao notion数据的新人引导机器人,并拿到了二等奖。 至此我们走上了AI应用的开发和学习的道路。下面是我和我的团队在这半年里面一起完成的关于AI应用相关的内容。
关于大模型的一些基本概念可以看这个链接: AI应用技术的分享
在这半年中我尝试了各类大模型,包括文字、图像和语音。以下将从这几个方面介绍我对这些大模型的认知以及我和我的团队基于这些大模型实现的应用。
这是一篇关于大模型应用和基础介绍的文章,主要是介绍AI可以做一些什么,因为我个人的水平和能力有限,会有很多内容出错或者表达偏差,欢迎指正。
文字推理及生成
文字推理类的大模型是以GPT为代表的一类通过问题(prompt)推导答案(answer)的大语言模型。 对于Gpt这一类的大语言模型的理解可以通过Ted Chiang发表的一篇文章理解:ChatGPT Is a Blurry JPEG of the Web
可以将ChatGPT等大语言模型视为网上所有文本的压缩数据。就像一张模糊的JPEG,是对图片的有损压缩。 GPT对文本内容的补全和JPEG数据恢复成图像,都是在已有数据基础上,根据概率,对缺失数据进行填充。
当前比较主流的文字推理大模型
| 名称 | 网站 | 上下文大小 | 特点 |
|---|---|---|---|
| GPT(3.5&4) | https://beta.openai.com/ | 4K-32K | 非开源,GPT-4的能力在数学、代码方面暂时是最强的 |
| LLAMA1&2) | https://github.com/facebookresearch/llama | / | meta开源的,最近最火的,易于微调 |
| Claude(1&2) | https://claude.ai/ | 100K(约65000单词) | 可以接收PDF/txt附件,实现超长文本的翻译,总结,以及代码翻译 |
| 通义千问 | https://tongyi.aliyun.com/ | 4k | 可以说是国内性能比较好的大模型,在阿里灵积模型开放api,v1版本开源。 |
| ChatGlm-6b | https://maas.aminer.cn/ | 4k-16k | 国内最早开源的一批家用显卡可以部署和微调的模型 |
具体的综合对比可以参考大语言模型的综述
基于知识库的企业问答机器人ASKIO
Askio是我这半年里面最主要的项目,其本质是一个基于本地知识库的问答机器人。 整个项目的核心有两个,一个是如何将非结构化数据转换为结构化数据, 第二个是如何实现高效和高质量的检索并与LLM交互。
功能介绍及演示视频:https://www.bilibili.com/video/BV1Zz4y1g77J
Askio的国内官网:https://www.askio.xyz
Askio的产品介绍图如下:
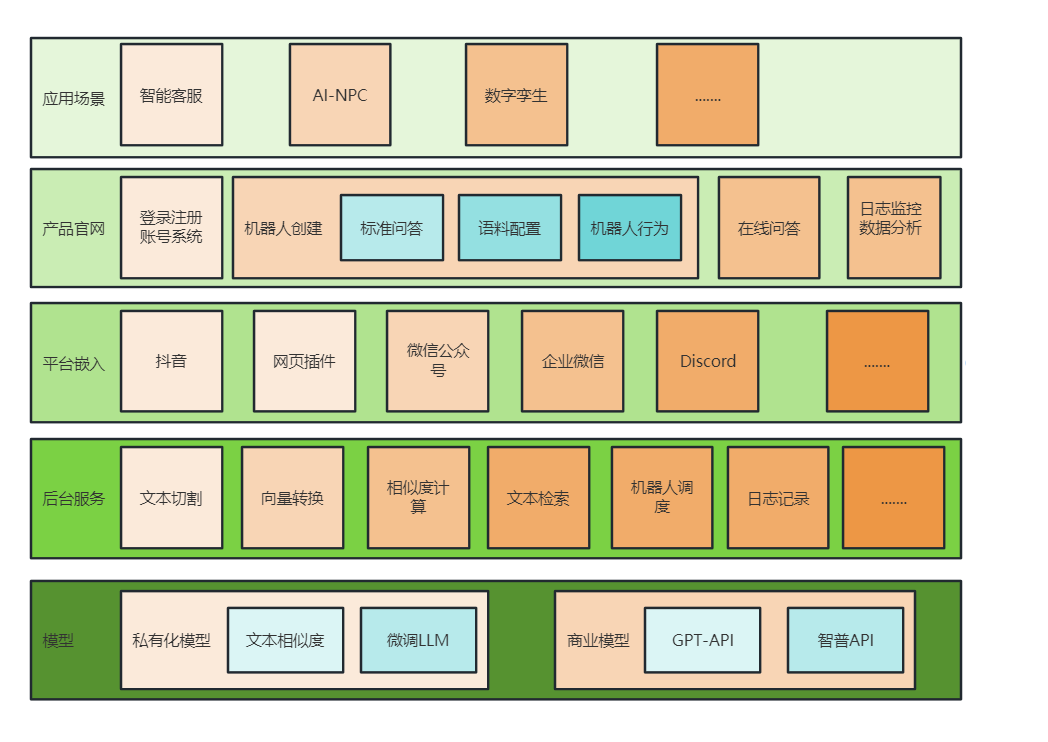
关于以下的技术实现和细节,如果你有任何的想法和思路,或者想探索,都可以跟我来聊一聊:
- 如何将非结构数据转换为结构化数据,采用向量(embeding)、知识图谱等方法,如何高效和准确的实现。
- 基于向量数据库的混合检索、稀疏向量匹配、源数据召回、上下文压缩等问题。
图像生成及推理
图像生成领域的大模型和软件在业界中还是比较少的,出名的有MJ(midjourney)和SD(stable diffusion)
Midjourney在参考CLIP及Diffusion开源模型的基础上,构建自己的垂类SaaS产品。
MJ更像是众多sd模型的混合版本,根据提示词实现了模型风格,模型类型的自动选择。
在图像生成的领域,我没有进行模型的微调和模型底层开发相关的经验,仅有使用SD的一些应用经验。
简单的描述一下图像生成大模型的实现原理,以下是基于SD1.0和SD1.5版本的,近期SDXL的出现,其实现原理更复杂和精细。
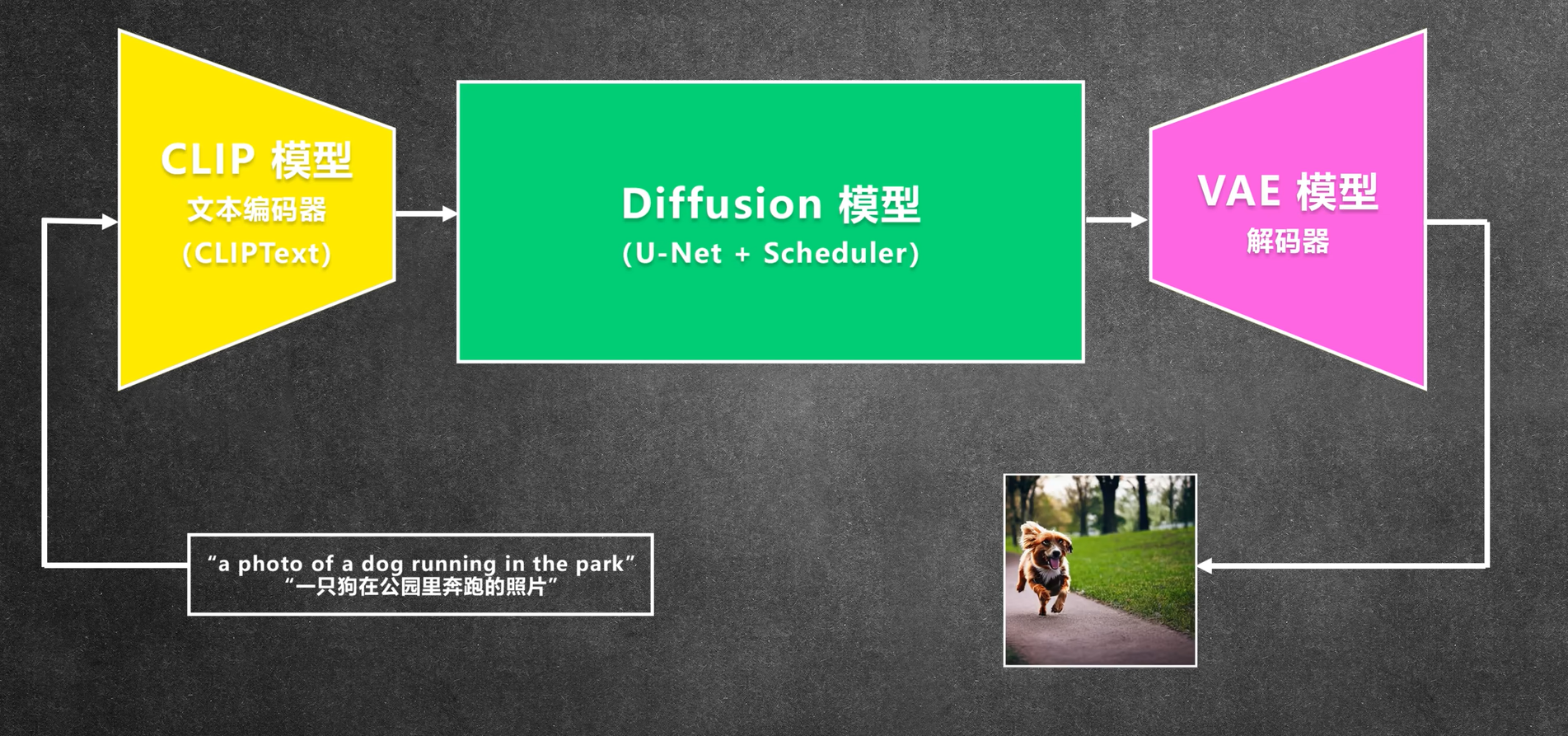
其本质跟语言类的推理大模型是一样,是一个端到端的推理模型,只是输入的编码器和输出的解码器不一样。
简单易懂的 Diffusion Model 解释:https://www.youtube.com/watch?v=1CIpzeNxIhU
很棒的Stable Diffusion解释:https://jalammar.github.io/illustrated-stable-diffusion/
同样很棒的SD解释:https://medium.com/@steinsfu/stable-diffusion-clearly-explained-ed008044e07e
一些有趣的图像/视频模型推荐
| 模型名称 | github地址 | 功能 | 其他 |
|---|---|---|---|
| stable diffusion | https://github.com/CompVis/stable-diffusion | 根据文字/图片生成图片 | webUI及部署方法可以参考秋葉aaaki的视频 |
| SadTalk | https://github.com/OpenTalker/SadTalker | 基于照片和语音生成人物表情和嘴型视频 | sd webui上有集成插件 |
| segment anything | https://github.com/facebookresearch/segment-anything | meta开源的抠图大模型,可以根据文本抠图 | sd webui上有集成插件 |
| DrapGen | https://github.com/XingangPan/DragGAN | 可以拖动图片中任意物体的大模型 |
基于SD的AI视频制作
Marco(彭生)和我在最近的几个月里面,一直在研究AI视频制作,采用了很多方法和尝试。 在AI视频生成和制作中,我认为最难和最复杂的和正常拍视频是一样的,是想法和脚本构思,其次是AI如何配合这些想法和剧情脚本,包括后期如何让AI视频不闪之类的。
AI视频的展示
这是Marco制作的第一个公开的AI视频 当一个铃铛说...点我:https://www.bilibili.com/video/BV1d94y1i7PA/
这是一个连续剧,下一集即将完成,同时剧情和技术也有了很大的提升。
基于SadTalk的图片生成数字人
下面这个demo是采用Askio的英文介绍通过SadTalk生成的AI视频
这个demo是采用中文东北话生成的AI视频
原始图像是通过SD生成
语音生成及推理
关于市面上的语音合成技术
语音合成的两种方式:TTS和VCS
TTS和VCS是两种不同的技术,分别用于语音合成和语音转换。
TTS(Text-to-Speech)是一种语音合成技术,它将文本转换为人类可以听懂的语音。使用TTS技术,计算机可以自动将文本转换为语音,而无需人类语音演讲者的参与。TTS技术可以用于语音助手、自动语音应答系统、有声读物等领域。
VCS(Voice Conversion System)是一种语音转换技术,它可以将一个人的语音转换成另一个人的语音,而不改变语音的内容和意义。VCS技术可以用于语音模仿、语音变声、语音匹配等领域。
虽然TTS和VCS都涉及到语音技术,但它们的应用场景和技术原理都有所不同。TTS主要用于将文本转换为语音,而VCS则用于语音转换和模仿。
基于VIST的语音克隆
当前我只研究了一下TTS相关的合成技术,没有研究VCS相关的技术,以下都是属于TTS的模型训练方式
当前主流的模型有基于Vits模型衍生出来的一系列模型和类似FastSpeech的Parallel模型,都可以在极低的训练数据下产生不错的效果
这两种模型的实现方式是非常类似的,训练过程也基本一致。
训练一个语音模型需要经历以下的步骤:
准备预训练模型,也可以称为底模
准备训练的数据集,一般10-20短10秒以内的语音文件
对数据集进行降噪,并进行语音识别
最终标准的训练数据为10-20组短语音文件和对应的中文识别文字
进行训练(通常采用GPU进行),大约100个训练周期,约为10-20分钟,可以生成一个微调模型,也就是最终的语音模型。
该模型的效果取决于底模(预训练模型)+训练数据和训练时长决定,按照上面的训练方式可以实现大约70%的相似效果。
混合应用
这边定义的混合应用,一般是指使用多个模型或者多个能力串行/并行实现的一个软件或者功能。
例如数字人/AI孪生就是比较复杂的应用,一般包含了语音识别、语音克隆、语音合成、文本驱动3D模型、情感分析等模块,每一个模块或多或少都应用到了大模型的能力。
AI语音交互抖音小程序
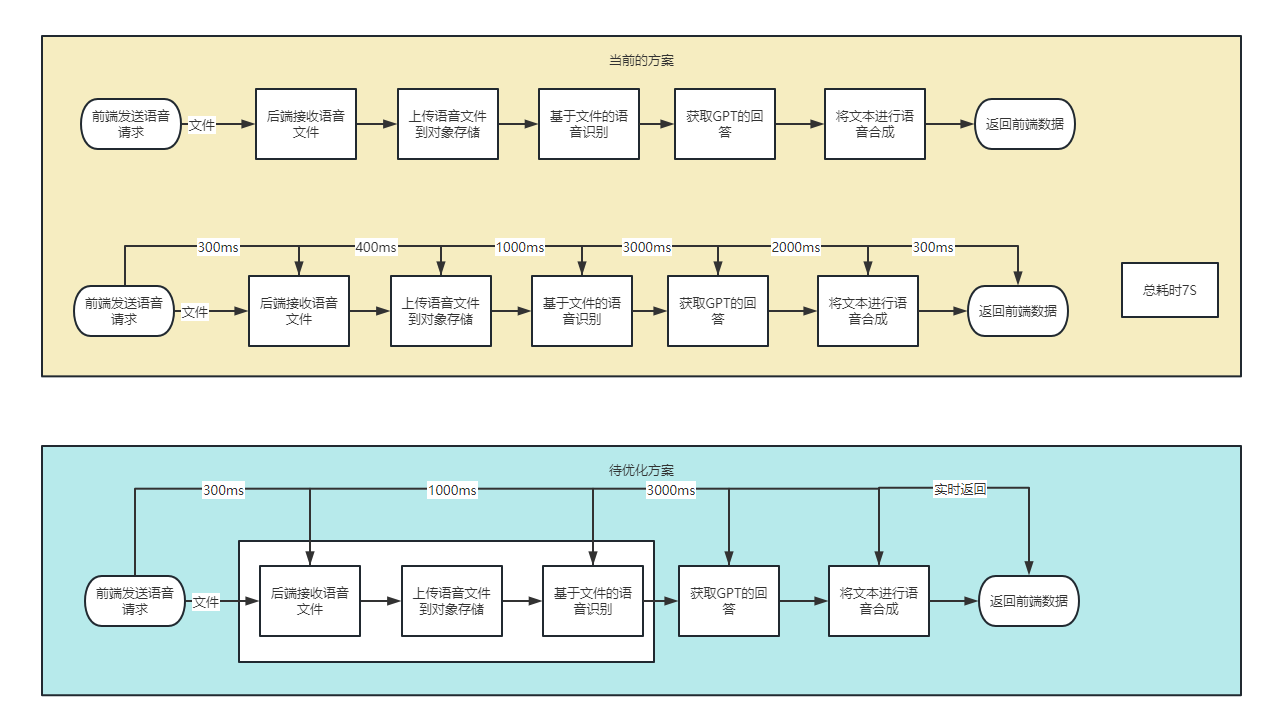
我和我的团队在抖音上开发了一款小程序,可以实现语音对话功能,实现了数字人的一部分功能。 demo如下:
其具体的实现逻辑如下:
数字人相关
数字人和数字孪生在GPT出现之后便非常的火热,从直播带货到知识区UP主打造自己的分身,各种技术层出不穷。
在距离用户最近的展示层,可以是基于unity、meta human、UE等三维建模软件实现的3d人物模型。很多公司也在研究文本/语音驱动3维模型,基于脸部和骨骼模型进行 动作生成。最后是结合语音技术实现一条对话流水线。
基于Unity的数字人构建
下面这个demo是通过unity和gpt实现的数字人
最后
技术的迭代日新月异,AI给了我们对无穷的想象力的实现能力,从始至终,我都认为AI是可以有效的提升工作和娱乐效率,虽然不一定是解放生产力,但肯定不是替代人类。