
关于AI技术相关的分享
关于AI技术相关的分享
以语言大模型应用做为例子,往往一个AI应用包含以下的层 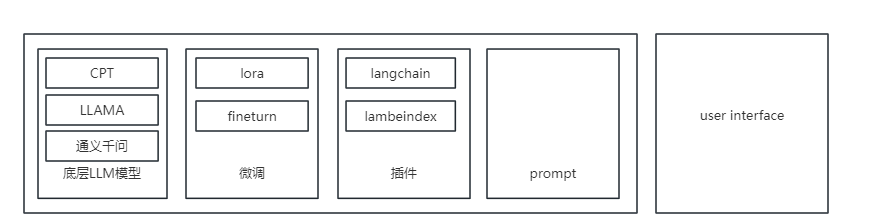 istrat
istrat
底层大模型 主要负责推理
微调 是可选项
插件和prompt,主要负责功能的特异化,桥接大模型和用户。
底层大模型主要是国内外开源的模型,一般具有API,可以输入文本或者图像(如果模型支持多模态)数据,模型进行推理,输出文字或者图像。
OpenAI的模型介绍和API介绍:https://beta.openai.com/overview
大模型的试用:https://poe.com/
国内大模型的API调用和申请:https://dashscope.console.aliyun.com/
Chatglm的github: htts://github.com/THUDM/ChatGLM-6B
大模型相关
大模型相关的开发和研究主要是ML(Machine Learning)和DS (Data Scientist)的领域。我对此没有太多的了解和研究。仅知道以下的内容:
底层模型现在主流的是采用BERT(Bidirectional Encoder Representations from Transformers)
BERT是基于Transformer模型的一种预训练语言模型,它在自然语言处理领域中表现出了非常出色的性能。Transformer是一种用于序列到序列(Sequence-to-Sequence)学习的神经网络模型,它在自然语言处理领域中被广泛应用。
BERT模型使用了Transformer编码器(Transformer Encoder)的部分结构,主要包括Self-Attention、Feed-Forward和Layer Normalization等组件。在BERT的预训练过程中,使用了大量的无标注数据来训练模型,使得模型能够有效地学习文本中的语义信息,从而提高了在下游任务中的性能表现。
相关的课程可以看清华大学的公开课:https://www.bilibili.com/video/BV1UG411p7zv/?spm_id_from=333.337.search-card.all.click

微调、Lora和嵌入
模型微调(Fine-tuning)是指在一个预训练好的模型上,针对特定任务或数据集进行进一步的训练,以提高模型在该任务或数据集上的性能。微调通常涉及对模型的最后几层进行调整,称为顶部层,以使其适应新任务或数据集的要求。微调的目的是通过利用预先训练好的模型的通用特征,加速模型在新任务上的学习过程。
Lora(Low-Rank Adaptation of Large Language Models)是一种针对大型语言模型的微调技术,旨在通过降低模型参数的秩(Rank)来提高模型的适应性和泛化能力。
在自然语言处理任务中,大型语言模型(例如BERT、GPT等)通常需要大量的参数来进行训练,以便学习到复杂的语言表征和模式。然而,在实际应用中,这些模型往往需要在特定领域或任务上进行微调,以提高其性能。传统的微调方法通常需要重新训练整个模型,这是非常耗时和计算资源密集的。而Low-Rank Adaptation技术则可以通过对预训练模型进行低秩近似,来实现快速且高效的微调。
具体来说,Low-Rank Adaptation技术通过对预训练模型的参数矩阵进行SVD分解,将其分解为多个低秩矩阵的乘积形式,从而降低参数的秩。这样做的好处是可以减少微调过程中需要更新的参数数量,从而提高微调的速度和效率,并且可以减少过拟合的风险,从而提高模型的泛化能力。
实验结果表明,Low-Rank Adaptation技术在各种自然语言处理任务上均取得了很好的效果,包括文本分类、情感分析、问答等任务。同时,由于其高效性和泛化能力,Low-Rank Adaptation技术也被广泛应用于各种实际应用场景中,如文本摘要、机器翻译、对话系统等。
在自然语言处理中,嵌入(Embedding)是指将离散的文本单元(例如单词、句子)映射到低维度的实数向量空间中的过程。在大语言模型中,嵌入通常用于将输入的文本序列转换为连续的实数向量序列,以便于神经网络的处理。
嵌入主要是在模型中的encoding中使用,同时也可以用于基于知识库的文本问答,基于向量数据库实现,其本质类似于在大语言模型上面增加了一个插件,将于知识库相关的内容提取出来,组合成prompt让大语言模型进行推理。
插件,应用层开发
在微调和Lora上面就是主要的应用层开发,包括一系列的插件开发,应用功能开发等。
其本质是将用户的输入的数据进行特异化,通过应用、脚本、插件等能力生成prompt,再将prompt发送给模型推理,获取推理后的答案,进行封装、二次加工和展示。整个过程很像设计模式中的装饰器模式,在不改变大模型的基础上增加大模型的能力。
相关的学习资料
Langchain的github : https://github.com/langchain-ai/langchain
llama__index的github :_https://github.com/jerryjliu/llama_index