
基础模式 自动化布局
基础模式 自动化布局
2.5 Automated Placement 自动化布局(Pod的放置)
Automated Placement is the core function of the Kubernetes scheduler for assigning new Pods to nodes satisfying container resource requests and honoring scheduling policies. This pattern describes the principles of Kubernetes’ scheduling algorithm and the way to influence the placement decisions from the outside.
自动化放置(分配?调度)是Kubernetes调度器的核心功能,用于将新POD分配给满足容器资源请求的节点,并遵守调度策略。该模式描述了Kubernetes调度算法的原理以及从外部影响布局决策的方式。
2.5.1 Problem 问题
A reasonably sized microservices-based system consists of tens or even hundreds of isolated processes. Containers and Pods do provide nice abstractions for packaging and deployment but do not solve the problem of placing these processes on suitable nodes. With a large and ever-growing number of microservices, assigning and placing them individually to nodes is not a manageable activity.
一个规模合理的基于微服务的系统由数十个甚至数百个孤立的进程组成。容器和pod确实为打包和部署提供了很好的抽象,但并不能解决将这些进程放置在合适节点上的问题。随着微型服务数量的不断增加,将它们单独分配和放置到节点并不是一项可管理的活动。
Containers have dependencies among themselves, dependencies to nodes, and resource demands, and all of that changes over time too. The resources available on a cluster also vary over time, through shrinking or extending the cluster, or by having it consumed by already placed containers. The way we place containers impacts the availability, performance, and capacity of the distributed systems as well. All of that makes scheduling containers to nodes a moving target that has to be shot on the move.(这句翻译有问题,暂时跳过)
容器之间有依赖关系、对节点的依赖关系和资源需求,所有这些都会随着时间的推移而变化。集群上可用的资源也会随着时间的推移而变化,通过收缩或扩展集群,或者让已经放置的容器消耗集群。我们放置容器的方式也会影响分布式系统的可用性、性能和容量。所有这些都使得将容器调度到节点这一过程中的目标,必须在进行中完成。
2.5.2 Solution 解决方案
In Kubernetes, assigning Pods to nodes is done by the scheduler. It is an area that is highly configurable, still evolving, and changing rapidly as of this writing. In this chapter, we cover the main scheduling control mechanisms, driving forces that affect the placement, why to choose one or the other option, and the resulting consequences. The Kubernetes scheduler is a potent and time-saving tool.It plays a fundamental role in the Kubernetes platform as a whole, but similarly to other Kubernetes components (API Server, Kubelet), it can be run in isolation or not used at all.
在Kubernetes中,将Pod分配给节点是由调度器完成的。在撰写本文时,这是一个高度可配置、仍在发展和快速变化的领域。在本章中,我们将介绍主要的调度控制机制、影响布局的驱动力、为什么选择一个或另一个选项以及由此产生的后果。Kubernetes调度器是一个功能强大且节省时间的工具。它在整个Kubernetes平台中起着基础性作用,但与其他Kubernetes组件(API服务器、Kubelet)类似,它可以单独运行或根本不使用。
At a very high level, the main operation the Kubernetes scheduler performs is to retrieve each newly created Pod definition from the API Server and assign it to a node. It finds a suitable node for every Pod (as long as there is such a node), whether that is for the initial application placement, scaling up, or when moving an application from an unhealthy node to a healthier one. It does this by considering runtime dependencies, resource requirements, and guiding policies for high availability, by spreading Pods horizontally, and also by colocating Pods nearby for performance and low-latency interactions. However, for the scheduler to do its job correctly and allow declarative placement, it needs nodes with available capacity, and containers with declared resource profiles and guiding policies in place. Let’s look at each of these in more detail.
在很高的层面上来说,Kubernetes调度器执行的主要操作是从API服务器中检索每个新创建的Pod定义,并将其分配到节点上。它为每个Pod找到一个合适的节点(只要有这样一个节点),无论是用于初始应用程序放置、扩展,还是将应用程序从不健康的节点移动到更健康的节点。它通过考虑运行时依赖关系、资源需求和高可用性指导策略、水平分布pod以及将pod集中在附近以实现性能和低延迟交互来实现这一点。但是,为了让调度器正确地执行其工作并允许声明式放置,它需要具有可用容量的节点,以及具有声明的资源配置文件和指导策略的容器。让我们更详细地了解其中的每一项。
2.5.2.1 Available Node Resources 可用节点资源
First of all, the Kubernetes cluster needs to have nodes with enough resource capacity to run new Pods. Every node has capacity available for running Pods, and the scheduler ensures that the sum of the resources requested for a Pod is less than the available allocatable node capacity. Considering a node dedicated only to Kubernetes, its capacity is calculated using the formula in Example 6-1.
首先,Kubernetes集群需要具有足够资源容量的节点来运行新的POD。每个节点都有运行Pod的可用容量,调度器确保Pod请求的资源总和小于可用的可分配节点容量。考虑到仅用于Kubernetes的节点,使用示例6-1中的公式计算其容量。
Example 6-1. Node capacity
Allocatable [capacity for application pods] =
Node Capacity [available capacity on a node]
- Kube-Reserved [Kubernetes daemons like kubelet, container runtime]
- System-Reserved [OS system daemons like sshd, udev]
If you don’t reserve resources for system daemons that power the OS and Kubernetes itself, the Pods can be scheduled up to the full capacity of the node, which may cause Pods and system daemons to compete for resources, leading to resource starvation issues on the node. Also keep in mind that if containers are running on a node that is not managed by Kubernetes, the resources used by these containers are not reflected in the node capacity calculations by Kubernetes.
如果不给K8s系统本身和那些支撑系统的守护进程预留系统资源,则POD的调度可能会达到节点的最大容量,这可能会导致POD和系统守护进程争夺资源,从而导致节点上的资源不足问题。还请记住,如果容器运行在非Kubernetes管理的节点上,这些容器使用的资源不会反映在Kubernetes的节点容量计算中。
A workaround for this limitation is to run a placeholder Pod that doesn’t do anything, but has only resource requests for CPU and memory corresponding to the untracked containers’ resource use amount. Such a Pod is created only to represent and reserve the resource consumption of the untracked containers and helps the scheduler build a better resource model of the node.
为了解决上面说的这个问题,可用通过运行一个占位符Pod来实现,它不做任何事情,只是请求与那些未跟踪(不属于K8s的)容器资源使用量相对应的CPU和内存的资源。创建这样的Pod只是为了表示和保留未跟踪容器的资源消耗,并帮助调度器构建更好的节点资源模型。
2.5.2.2 Container Resource Demands 容器资源声明
Another important requirement for an efficient Pod placement is that containers have their runtime dependencies and resource demands defined. We covered that in more detail in Chapter 2, Predictable Demands. It boils down to having containers that declare their resource profiles (with request and limit) and environment dependencies such as storage or ports. Only then are Pods sensibly assigned to nodes and can run without affecting each other during peak times.
有效放置Pod的另一个重要要求,是容器定义了其运行时依赖项和资源需求。我们在本章第1节“可预测需求”中更详细地介绍了这一点。它归结为具有声明其资源配置文件(带有请求和限制)和环境依赖项(如存储或端口)的容器。只有这样,POD才能合理地分配给节点,并且在高峰时间运行时不会相互影响。
2.5.2.3 Placement Policies 放置策略
The last piece of the puzzle is having the right filtering or priority policies for your specific application needs. The scheduler has a default set of predicate and priority policies configured that is good enough for most use cases. It can be overridden during scheduler startup with a different set of policies, as shown in Example 6-2.
最后一个难题是为特定应用程序需求制定正确的过滤或优先级策略。调度器配置了一组默认的谓词和优先级策略,对于大多数用例来说已经足够好了。在调度程序启动期间,可以使用一组不同的策略覆盖它,如示例6-2所示。
Example 6-2. An example scheduler policy
{
"kind" : "Policy",
"apiVersion" : "v1",
"predicates" : [
{"name" : "PodFitsHostPorts"},
{"name" : "PodFitsResources"},
{"name" : "NoDiskConflict"},
{"name" : "NoVolumeZoneConflict"},
{"name" : "MatchNodeSelector"},
{"name" : "HostName"}
],
"priorities" : [
{"name" : "LeastRequestedPriority", "weight" : 2},
{"name" : "BalancedResourceAllocation", "weight" : 1},
{"name" : "ServiceSpreadingPriority", "weight" : 2},
{"name" : "EqualPriority", "weight" : 1}
]
}
#Predicates are rules that filter out unqualified nodes. For example, PodFitsHostsPorts schedules Pods to request certain fixed host ports only on those nodes that have this port still available.
#Predicates是过滤出那些不符合的节点的规则。例如,PodFitsHostsPorts将请求某些固定主机端口的pod调度到那些仍有此端口可用的节点上。
#Priorities are rules that sort available nodes according to preferences. For example, LeastRequestedPriority gives nodes with fewer requested resources a higher priority.
#Priorities是根据表现对可用节点排序的规则。例如,LeastRequestedPriority为请求资源较少的节点提供了更高的优先级。
Scheduler policies and custom schedulers can be defined only by an administrator as part of the cluster configuration. As a regular user you just can refer to predefined schedulers.
作为群集配置的一部分,调度器策略和自定义调度器只能由管理员进行定义。作为普通用户,只需参考预定义的调度程序即可。
Consider that in addition to configuring the policies of the default scheduler, it is also possible to run multiple schedulers and allow Pods to specify which scheduler to place them. You can start another scheduler instance that is configured differently by giving it a unique name. Then when defining a Pod, just add the field .spec.schedulerName with the name of your custom scheduler to the Pod specification and the Pod will be picked up by the custom scheduler only.
考虑到除了配置默认调度器的策略外,还可以运行多个调度器,并允许POD指定放置它们的调度器。可以通过不同的命名来启动另一个配置不同的调度程序实例。然后在定义Pod时,只需将带有自定义调度程序名称的.spec.schedulerName字段添加到Pod规范中,Pod将仅由自定义调度程序拾取。
2.5.2.4 Scheduling Process 调度进程
Pods get assigned to nodes with certain capacities based on placement policies. For completeness, Figure 6-1 visualizes at a high level how these elements get together and the main steps a Pod goes through when being scheduled.
POD根据放置策略分配给具有特定容量的节点。为了完整起见,图6-1从较高的层次上展示了这些元素是如何组合在一起的,以及Pod在调度时所经历的主要步骤。
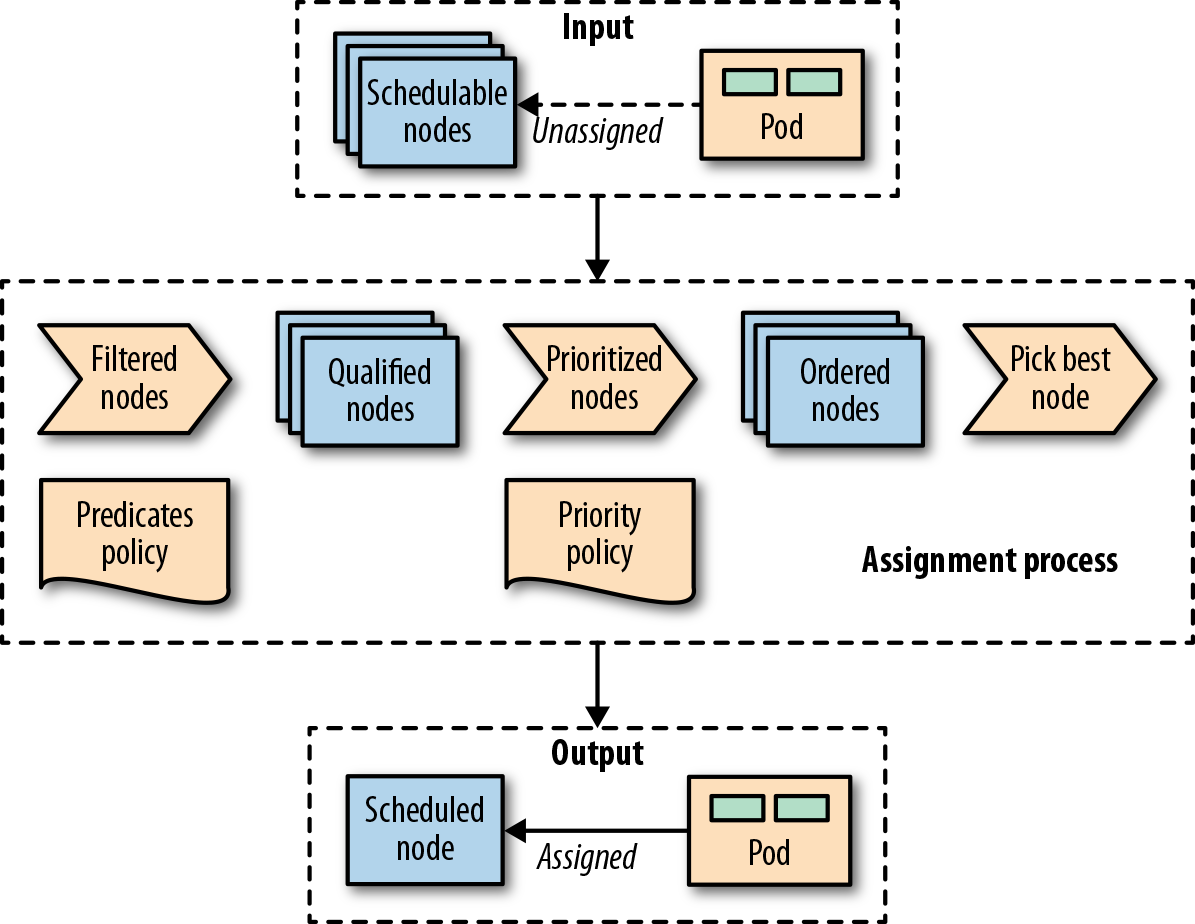
Figure 6-1. A Pod-to-node assignment process
As soon as a Pod is created that is not assigned to a node yet, it gets picked by the scheduler together with all the available nodes and the set of filtering and priority policies. In the first stage, the scheduler applies the filtering policies and removes all nodes that do not qualify based on the Pod’s criteria. In the second stage, the remain‐ing nodes get ordered by weight. In the last stage the Pod gets a node assigned, which is the primary outcome of the cheduling process.
一旦创建了一个尚未分配给节点的Pod,调度程序就会将其与所有可用节点以及一组筛选和优先级策略一起拾取。在第一阶段,调度器应用过滤策略,并根据Pod的标准删除所有不符合条件的节点。在第二阶段,剩余节点按权重排序。在最后一个阶段,Pod获得分配的节点,这是调度过程的主要结果。
In most cases, it is better to let the scheduler do the Pod-to-node assignment and not micromanage the placement logic. However, on some occasions, you may want to force the assignment of a Pod to a specific node or a group of nodes. This assignment can be done using a node selector. .spec.nodeSelector is Pod field and specifies a map of key-value pairs that must be present as labels on the node for the node to be eligible to run the Pod. For example, say you want to force a Pod to run on a specific node where you have SSD storage or GPU acceleration hardware. With the Pod definition in Example 6-3 that has nodeSelector matching disktype: ssd, only nodes that are labeled with disktype=ssd will be eligible to run the Pod.
在大多数情况下,最好让调度器执行Pod到节点的分配,而不是微观管理放置逻辑。但是,在某些情况下,可能希望强制将Pod分配给特定节点或一组节点。可以使用节点选择器完成此分配。spec.nodeSelector是Pod字段,指定了一组键值对,只有标记了满足键值对中条件的节点,才有资格运行这些Pod。例如,假设你希望强制Pod在具有SSD存储或GPU加速硬件的特定节点上运行。对于示例6-3中具有节点选择器匹配disktype:ssd的Pod定义,只有标记为disktype=ssd的节点才有资格运行Pod。
Example 6-3. Node selector based on type of disk available
apiVersion: v1
kind: Pod
metadata:
name: random-generator
spec:
containers:
- image: k8spatterns/random-generator:1.0
name: random-generator
nodeSelector:
disktype: ssd
#Set of node labels a node must match to be considered to be the node of this Pod
In addition to specifying custom labels to your nodes, you can use some of the default labels that are present on every node. Every node has a unique kubernetes.io/host name label that can be used to place a Pod on a node by its hostname. Other default labels that indicate the OS, architecture, and instance-type can be useful for placement too.
除了为节点指定自定义标签外,还可以使用每个节点上存在的一些默认标签。每个节点都有一个唯一的kubernetes.io/host name标签,可用于根据其主机名在节点上放置Pod。指示操作系统、体系结构和实例类型的其他默认标签对于放置Pod也是很有用的。
2.5.2.5 Node Affinity 节点关联(亲和性)
Kubernetes supports many more flexible ways to configure the scheduling processes.One such a feature is node affinity, which is a generalization of the node selector approach described previously that allows specifying rules as either required or preferred. Required rules must be met for a Pod to be scheduled to a node, whereas preferred rules only imply preference by increasing the weight for the matching nodes without making them mandatory. Besides, the node affinity feature greatly expands the types of constraints you can express by making the language more expressive with operators such as In, NotIn, Exists, DoesNotExist, Gt, or Lt. Example 6-4 demonstrates how node affinity is declared.
Kubernetes支持许多更灵活的方式来配置调度过程。其中一个功能是节点关联,它是前面描述的节点选择器方法的泛化,允许根据需要或首选指定规则。Pod调度到节点时必须满足所需的规则,而首选规则仅通过增加匹配节点的权重来暗示偏好,而不强制要求它们。此外,节点关联功能通过使用诸如In、NotIn、Exists、DOESNOTEXTIST、Gt或Lt等运算符使语言更具表现力,从而大大扩展了可以表达的约束类型。示例6-4演示了如何声明节点关联。
Example 6-4. Pod with node affinity
apiVersion: v1
kind: Pod
metadata:
name: random-generator
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
#Hard requirement that the node must have more than three cores (indicated by a node label) to be considered in the scheduling process. The rule is not reevaluated during execution if the conditions on the node change.
nodeSelectorTerms:
#Match on labels. In this example all nodes are matched that have a label number Cores with a value greater than 3.
- matchExpressions:
- key: numberCores
operator: Gt
values: [ "3" ]
preferredDuringSchedulingIgnoredDuringExecution:
#Soft requirements, which is a list of selectors with weights. For every node, the sum of all weights for matching selectors is calculated, and the highest-valued node is chosen, as long as it matches the hard requirement.
- weight: 1
preference:
matchFields:
#Match on a field (specified as jsonpath). Note that only In and NotIn are allowed as operators, and only one value is allowed to be given in the list of values.
- key: metadata.name
operator: NotIn
values: [ "master" ]
containers:
- image: k8spatterns/random-generator:1.0
name: random-generator
2.5.2.6 Pod Affinity and Antiaffinity Pod关联(亲和)与反关联(为了保持和Node Affinity 一致)
Node affinity is a more powerful way of scheduling and should be preferred when nodeSelector is not enough. This mechanism allows constraining which nodes a Pod can run based on label or field matching. It doesn’t allow expressing dependencies among Pods to dictate where a Pod should be placed relative to other Pods. To express how Pods should be spread to achieve high availability, or be packed and colocated together to improve latency, Pod affinity and antiaffinity can be used.
节点关联是一种更强大的调度方式,当nodeSelector不够用时,应该优先使用。该机制允许基于标签或字段匹配来约束Pod可以运行的节点。它不允许表达Pod之间的依赖关系来决定一个Pod相对于其他Pod应该放置在哪里。为了说明Pod应该如何传播以实现高可用性,或者如何打包并共同放置以提高延迟,可以使用Pod关联和反关联的方法。
Node affinity works at node granularity, but Pod affinity is not limited to nodes and can express rules at multiple topology levels. Using the topologyKey field, and the matching labels, it is possible to enforce more fine-grained rules, which combine rules on domains like node, rack, cloud provider zone, and region, as demonstrated in Example 6-5.
节点关联在节点粒度上工作,但Pod关联不限于节点,可以在多个拓扑级别上表达规则。使用topologyKey字段和匹配标签,可以实施更细粒度的规则,这些规则结合了节点、架构、云原生平台中的区域和领域等域上的规则,如示例6-5所示。
Example 6-5. Pod with Pod affinity
apiVersion: v1
kind: Pod
metadata:
name: random-generator
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchLabels:
confidential: high
topologyKey: security-zone
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchLabels:
confidential: none
topologyKey: kubernetes.io/hostname
containers:
- image: k8spatterns/random-generator:1.0
name: random-generator
#Required rules for the Pod placement concerning other Pods running on the target node.
#Label selector to find the Pods to be colocated with.
#The nodes on which Pods with labels confidential=high are running are supposed to carry a label security-zone. The Pod defined here is scheduled to a node with the same label and value.
#Antiaffinity rules to find nodes where a Pod would not be placed.
#Rule describing that the Pod should not (but could) be placed on any node where a Pod with the label confidential=none is running.
Similar to node affinity, there are hard and soft requirements for Pod affinity and antiaffinity, called requiredDuringSchedulingIgnoredDuringExecution and preferredDuringSchedulingIgnoredDuringExecution, respectively. Again, as with node affinity, there is the IgnoredDuringExecution suffix in the field name, which exists for future extensibility reasons. At the moment, if the labels on the node change and affinity rules are no longer valid, the Pods continue running, but in the future runtime changes may also be taken into account.
与节点关联类似,Pod关联和反关联性也有硬需求和软需求,分别称为_requiredDuringSchedulingIgnoredDuringExecution_和_PreferredDuringSchedulingIgnoredDuringExecution_。同样,与节点关联一样,字段名中也有_IgnoredDuringExecution_后缀,它的存在是为了将来的扩展性。此时,如果节点上的标签更改,并且关联规则不再有效,则POD将继续运行,但在将来的运行时,也可能会考虑更改。
2.5.2.7 Taints and Tolerations 污点(具体是指节点的特征,感觉是个标签一样的)和容忍
A more advanced feature that controls where Pods can be scheduled and are allowed to run is based on taints and tolerations. While node affinity is a property of Pods that allows them to choose nodes, taints and tolerations are the opposite. They allow the nodes to control which Pods should or should not be scheduled on them. A taint is a characteristic of the node, and when it is present, it prevents Pods from scheduling onto the node unless the Pod has toleration for the taint. In that sense, taints and tolerations can be considered as an opt-in to allow scheduling on nodes, which by default are not available for scheduling, whereas affinity rules are an opt-out by explicitly selecting on which nodes to run and thus exclude all the nonselected nodes.
一个更高级的特性是基于污点和容忍度来控制POD可以调度和允许运行的位置。节点亲和力(关联)是POD的一个属性,允许它们选择节点,而污点和容忍则相反。它们允许节点控制应该或不应该在其上调度哪些Pod。污点是节点的一个特征,当它存在时,它会阻止Pod调度到节点上,除非Pod容忍污点。从这个意义上讲,污点和容忍可以被视为一种选择加入,允许在节点上进行调度,默认情况下,这些节点不可用于调度,而关联规则则是一种选择退出,通过显式选择在哪些节点上运行,从而排除所有未选择的节点。
A taint is added to a node by using kubectl: kubectl taint nodes master noderole.kubernetes.io/master="true":NoSchedule, which has the effect shown in Example 6-6. A matching toleration is added to a Pod as shown in Example 6-7. Notice that the values for key and effect in the taints section of Example 6-6 and the tolerations: section in Example 6-7 have the same values.
通过使用kubectl:kubectl-taint-nodes-master noderole.kubernetes.io/master=“true”:NoSchedule,可以将污点添加到节点中,其效果如示例6-6所示。如例6-7所示,将容忍添加到Pod中。请注意,示例6-6的“污点”部分中的“关键点”和“效果”的值与示例6-7中的“容忍:部分”的值相同。
Example 6-6. Tainted node
apiVersion: v1
kind: Node
metadata:
name: master
spec:
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/master
#Taint on a node’s spec to mark this node as not available for scheduling except when a Pod tolerates this taint
Example 6-7. Pod tolerating node taints
apiVersion: v1
kind: Pod
metadata:
name: random-generator
spec:
containers:
- image: k8spatterns/random-generator:1.0
name: random-generator
tolerations:
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
#Tolerate (i.e., consider for scheduling) nodes, which have a taint with key noderole. kubernetes.io/master. On production clusters, this taint is set on the master node to prevent scheduling of Pods on the master. A toleration like this allows this Pod to be installed on the master nevertheless.
#Tolerate only when the taint specifies a NoSchedule effect. This field can be empty here, in which case the toleration applies to every effect.
There are hard taints that prevent scheduling on a node (effect=NoSchedule), soft taints that try to avoid scheduling on a node (effect=PreferNoSchedule), and taints that can evict already running Pods from a node (effect=NoExecute).
存在阻止在节点上调度的硬污点(effect=NoSchedule),尝试避免在节点上调度的软污点(effect=PreferNoSchedule),以及可以从节点中逐出已经运行的pod的污点(effect=NoExecute)。
Taints and tolerations allow for complex use cases like having dedicated nodes for an exclusive set of Pods, or force eviction of Pods from problematic nodes by tainting those nodes.
污点和容忍允许复杂的用例,比如为一组排他的POD设置专用节点,或者通过污点这些节点强制从有问题的节点中逐出POD。
You can influence the placement based on the application’s high availability and performance needs, but try not to limit the scheduler too much and back yourself into a corner where no more Pods can be scheduled, and there are too many stranded resources. For example, if your containers’ resource requirements are too coarsegrained, or nodes are too small, you may end up with stranded resources in nodes that are not utilized.
你可以根据应用程序的高可用性和性能需求来影响放置,但不要尝试过多地限制调度器,让自己回到一个无法安排更多POD的角落,因为那里有太多搁浅的资源。例如,如果容器的资源需求过于粗粒度,或者节点太小,那么最终可能会导致节点中的资源无法使用。
In Figure 6-2, we can see node A has 4 GB of memory that cannot be utilized as there is no CPU left to place other containers. Creating containers with smaller resource requirements may help improve this situation. Another solution is to use the Kubernetes descheduler, which helps defragment nodes and improve their utilization.
在图6-2中,我们可以看到节点A有4GB的内存无法使用,因为没有剩余的CPU来放置其他容器。创建资源需求较小的容器可能有助于改善这种情况。另一个解决方案是使用Kubernetes descheduler,这有助于对节点进行碎片整理并提高其利用率
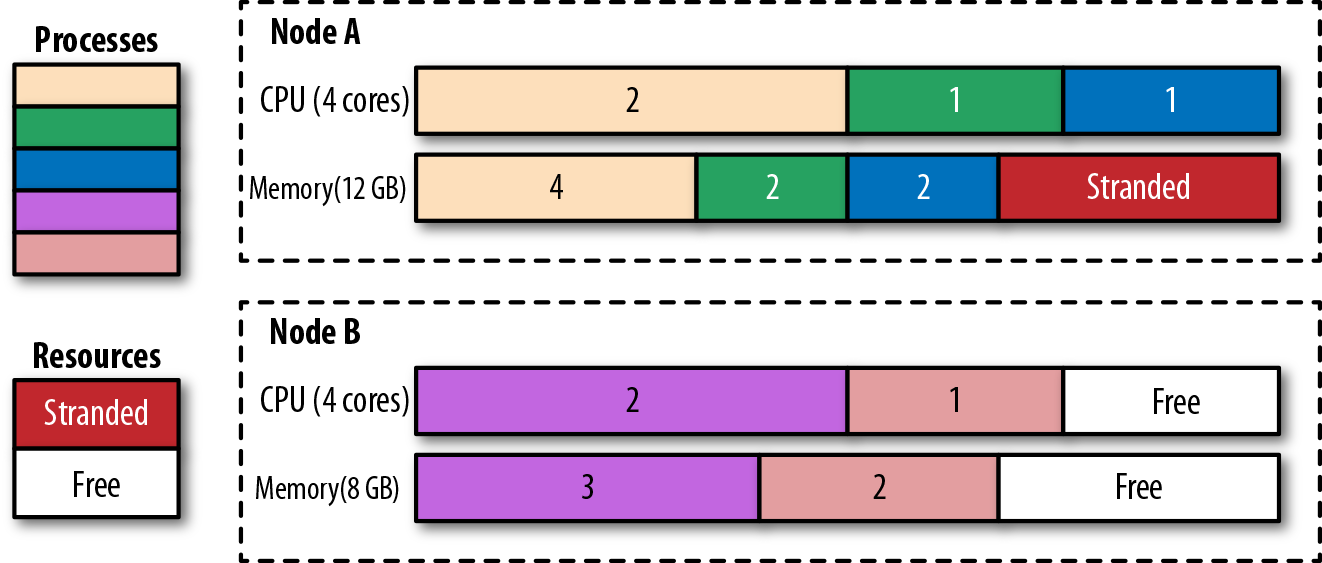
Figure 6-2. Processes scheduled to nodes and stranded resources
Once a Pod is assigned to a node, the job of the scheduler is done, and it does not change the placement of the Pod unless the Pod is deleted and recreated without a node assignment. As you have seen, with time, this can lead to resource fragmentation and poor utilization of cluster resources. Another potential issue is that the scheduler decisions are based on its cluster view at the point in time when a new Pod is scheduled. If a cluster is dynamic and the resource profile of the nodes changes or new nodes are added, the scheduler will not rectify its previous Pod placements. Apart from changing the node capacity, you may also alter the labels on the nodes that affect placement, but past placements are not rectified either.
一旦将Pod分配给节点,调度器的工作就完成了,并且它不会更改Pod的位置,除非在未分配节点的情况下删除并重新创建Pod。正如您所看到的,随着时间的推移,这可能会导致资源碎片化和集群资源利用率低下。另一个潜在问题是调度器的决策是基于其在调度新Pod时的集群视图。如果集群是动态的,并且节点的资源配置文件发生了更改或添加了新节点,则调度程序将不会纠正其以前的Pod位置。除了更改节点容量外,还可以更改节点上影响放置的标签,但也不会更正过去的放置。
All these are scenarios that can be addressed by the descheduler. The Kubernetes descheduler is an optional feature that typically is run as a Job whenever a cluster administrator decides it is a good time to tidy up and defragment a cluster by rescheduling the Pods. The descheduler comes with some predefined policies that can be enabled and tuned or disabled. The policies are passed as a file to the descheduler Pod, and currently, they are the following:
所有这些都是可由取消计划者(descheduler)解决的场景。Kubernetes descheduler是一个可选功能,通常在群集管理员决定通过重新调度POD来整理和整理群集时作为作业运行。descheduler附带了一些预定义的策略,可以启用、调整或禁用这些策略。这些策略作为文件传递给descheduler Pod,目前它们如下所示:
- RemoveDuplicates 移除副本策略 This strategy ensures that only a single Pod associated with a ReplicaSet or Deployment is running on a single node. If there are more Pods than one, these excess Pods are evicted. This strategy is useful in scenarios where a node has become unhealthy, and the managing controllers started new Pods on other healthy nodes. When the unhealthy node is recovered and joins the cluster, the number of running Pods is more than desired, and the descheduler can help bring the numbers back to the desired replicas count. Removing duplicates on nodes can also help with the spread of Pods evenly on more nodes when scheduling policies and cluster topology have changed after the initial placement. 此策略确保在单个节点上仅运行与ReplicaSet或Deployment关联的单个Pod。如果有多个POD,这些多余的POD将被逐出。在节点变得不健康,并且管理控制器在其他健康节点上启动新POD的情况下,此策略非常有用。当不健康节点恢复并加入集群时,正在运行的POD的数量超过预期,而descheduler可以帮助将这些数量恢复到预期的副本数量。当调度策略和集群拓扑在初始放置后发生更改时,删除节点上的重复项也有助于将POD均匀地分布在更多节点上。
- LowNodeUtilization 低节点利用率策略 This strategy finds nodes that are underutilized and evicts Pods from other overutilized nodes, hoping these Pods will be placed on the underutilized nodes, leading to better spread and use of resources. The underutilized nodes are identified as nodes with CPU, memory, or Pod count below the configured thresholds values. Similarly, overutilized nodes are those with values greater than the configured targetThresholds values. Any node between these values is appropriately utilized and not affected by this strategy. 此策略会发现未充分利用的节点,并从其他过度利用的节点中逐出POD,希望这些POD将放置在未充分利用的节点上,从而更好地传播和使用资源。未充分利用的节点被标识为CPU、内存或Pod计数低于配置阈值的节点。类似地,过度利用的节点是那些值大于配置的targetThresholds值的节点。这些值之间的任何节点都被适当地利用,并且不受此策略的影响。
- RemovePodsViolatingInterPodAntiAffinity 移除违反POD反亲和力(反关联)的策略 This strategy evicts Pods violating interpod antiaffinity rules, which could happen when the antiaffinity rules are added after the Pods have been placed on the nodes. 此策略会逐出违反内部POD反亲和规则的pod,这可能发生在将pod放置在节点上后添加反亲和规则时。
- RemovePodsViolatingNodeAffinity 移除违反POD亲和力(关联)的策略 This strategy is for evicting Pods violating node affinity rules. 此策略用于逐出违反节点关联规则的POD。
Regardless of the policy used, the descheduler avoids evicting the following:
无论使用何种策略,取消计划程序(descheduler )都会避免收回以下内容:
- Critical Pods that are marked with
scheduler.alpha.kubernetes.io/criticalpodannotation. - 用
scheduler.alpha.kubernetes.io/criticalpod注释标记的关键pod。 - Pods not managed by a ReplicaSet, Deployment, or Job.
- 不是由复制集、部署或作业管理的PODs。
- Pods managed by a DaemonSet.
- 由守护进程集管理的PODs。
- Pods that have local storage.
- 具有本地存储的Pods。
- Pods with PodDisruptionBudget where eviction would violate its rules.
- 带有PodDisruptionBudget的Pod,驱逐将违反其规则。
- Deschedule Pod itself (achieved by marking itself as a critical Pod).
- Deschedule Pod本身(通过将自身标记为关键Pod实现)。
Of course, all evictions respect Pods’ QoS levels by choosing Best-Efforts Pods first, then Burstable Pods, and finally Guaranteed Pods as candidates for eviction. See Chapter 2, Predictable Demands for a detailed explanation of these QoS levels.
当然,所有迁出都尊重POD的QoS级别,首先选择Best-Efforts的POD,然后选择Burstable POD,最后选择Guaranteed 的POD作为迁出的候选POD。有关这些QoS级别的详细说明,请参见第2章第1节中的“可预测需求”。
2.5.3 Discussion 讨论
Placement is an area where you want to have as minimal intervention as possible. If you follow the guidelines from Chapter 2, Predictable Demands and declare all the resource needs of a container, the scheduler will do its job and place the Pod on the most suitable node possible. However, when that is not enough, there are multiple ways to steer the scheduler toward the desired deployment topology. To sum up, from simpler to more complex, the following approaches control Pod scheduling (keep in mind, as of this writing, this list changes with every other release of Kubernetes):
放置Pod是一个希望尽可能少干预的领域。如果遵循“可预测的需求”章节中的指导原则并声明容器的所有资源需求,调度程序将完成其工作并将Pod放置在最合适的节点上。但是,当这还不够时,有多种方法可以将调度器导向所需的部署拓扑。总之,从简单到复杂,以下方法控制Pod调度(请记住,在撰写本文时,此列表会随着Kubernetes的其他版本而变化):
- nodeName 节点名称 The simplest form of hardwiring a Pod to a node. This field should ideally be populated by the scheduler, which is driven by policies rather than manual node assignment. Assigning a Pod to a node limits greatly where a Pod can be scheduled. This throws us back in to the pre-Kubernetes era when we explicitly specified the nodes to run our applications. 将Pod硬连接到节点的最简单形式。理想情况下,此字段应由调度程序填充,调度程序由策略驱动,而不是手动分配节点。将Pod分配给节点极大地限制了可以调度Pod的位置。这让我们回到了Kubernetes之前的时代,当时我们明确指定了运行应用程序的节点。
- nodeSelector 节点选择器 Specification of a map of key-value pairs. For the Pod to be eligible to run on a node, the Pod must have the indicated key-value pairs as the label on the node. Having put some meaningful labels on the Pod and the node (which you should do anyway), a node selector is one of the simplest acceptable mechanisms for controlling the scheduler choices. 键值对映射的规范。为了使Pod有资格在节点上运行,Pod必须具有指示的键值对作为节点上的标签。在Pod和节点上放置了一些有意义的标签(无论如何都应该这样做),节点选择器是控制调度器选择的最简单的可接受机制之一。
- Default scheduling alteration 默认调度替代 The default scheduler is responsible for the placement of new Pods onto nodes within the cluster, and it does it reasonably. However, it is possible to alter the filtering and priority policies list, order, and weight of this scheduler if necessary. 默认的调度器负责将新的pod放置到集群内的节点上,并且它做得很合理。但是,如果需要,可以更改此计划程序的筛选和优先级策略列表、顺序和权重。
- Pod affinity and antiaffinity Pod的亲和性和反亲和性 These rules allow a Pod to express dependencies on other Pods. For example, for an application’s latency requirements, high availability, security constraints, and so forth. 这些规则允许Pod表达对其他Pod的依赖关系。例如,对于应用程序的延迟要求、高可用性、安全约束等。
- Node affinity 节点的亲和性 This rule allows a Pod to express dependency toward nodes. For example, considering nodes’ hardware, location, and so forth. 此规则允许Pod表示对节点的依赖关系。例如,考虑节点的硬件、位置等。
- Taints and tolerations Taints and tolerations allow the node to control which Pods should or should not be scheduled on them. For example, to dedicate a node for a group of Pods, or even evict Pods at runtime. Another advantage of Taints and Tolerations is that if you expand the Kubernetes cluster by adding new nodes with new labels, you don’t need to add the new labels on all the Pods, but only on the Pods that should be placed on the new nodes. 污点和容忍允许节点控制应该或不应该在其上调度哪些pod。例如,将一个节点专用于一组pod,甚至在运行时收回pod。污点和容忍的另一个优点是,如果通过添加带有新标签的新节点来扩展Kubernetes集群,则不需要在所有POD上添加新标签,而只需要在应放置在新节点上的POD上添加新标签。
- Custom scheduler If none of the preceding approaches is good enough, or maybe you have complex scheduling requirements, you can also write your custom scheduler. A custom scheduler can run instead of, or alongside, the standard Kubernetes scheduler. A hybrid approach is to have a “scheduler extender” process that the standard Kubernetes scheduler calls out to as a final pass when making scheduling decisions. This way you don’t have to implement a full scheduler, but only provide HTTP APIs to filter and prioritize nodes. The advantage of having your scheduler is that you can consider factors outside of the Kubernetes cluster like hardware cost, network latency, and better utilization while assigning Pods to nodes. You can also use multiple custom schedulers alongside the default scheduler and configure which scheduler to use for each Pod. Each scheduler could have a different set of policies dedicated to a subset of the Pods. 如果前面的方法都不够好,或者你有复杂的调度需求,那么你也可以编写自定义调度程序。自定义调度器可以代替标准Kubernetes调度器运行,也可以与标准Kubernetes调度器并行运行。一种混合方法是有一个“调度器扩展器”进程,标准Kubernetes调度器在做出调度决策时调用该进程作为最终过程。通过这种方式,你不必实现完整的调度程序,只需提供HTTP API来过滤节点并确定其优先级。拥有调度器的优点在于,可以考虑在库伯网络集群之外的因素,如硬件成本、网络延迟和更好的利用,同时将节点分配给节点。你还可以在默认调度程序旁边使用多个自定义调度程序,并配置每个Pod要使用的调度程序。每个调度器可以有一组不同的策略,专用于POD的一个子集。
As you can see, there are lots of ways to control the Pod placement and choosing the right approach or combining multiple approaches can be challenging. The takeaway from this chapter is this: size and declare container resource profiles, label Pods and nodes accordingly, and finally, do only a minimal intervention to the Kubernetes scheduler.
正如你所见,有很多方法可以控制Pod的放置,选择正确的方法或组合多种方法可能是一项挑战。本章的要点是:调整和声明容器资源配置文件,相应地标记pod和节点,最后,只对Kubernetes调度程序进行最小的干预。