
FreeBe开发和测试协作的方式探讨
前两天Zoe跟我聊了一下,关于FreeBe项目开发上的一些现状,由于前端和后端都是由一位或者两位作者在更新和维护,项目更新和维护的进度很难把控, 同时群里有很多技术方面的小伙伴也想参与到项目的开发和维护中,所以就当前基于github托管模式,提一些便于团队协作的建议。
具体的实现可以通过会议讨论去定义,以下内容可以作为参考
多分支及权限设置
大约 3 分钟
前两天Zoe跟我聊了一下,关于FreeBe项目开发上的一些现状,由于前端和后端都是由一位或者两位作者在更新和维护,项目更新和维护的进度很难把控, 同时群里有很多技术方面的小伙伴也想参与到项目的开发和维护中,所以就当前基于github托管模式,提一些便于团队协作的建议。
具体的实现可以通过会议讨论去定义,以下内容可以作为参考
为了方便开发、测试和运维,这边建议采用两套服务器搭建开发环境和测试环境,采用GitHub作为代码托管,SonarCloud进行代码质量控制,DockerHub作为镜像托管,Git Action作为流水线控制,腾讯云作为服务器。 这样每次开发完成代码更新,测试链接就可以实时展示更新后的产品,方便demo展示和进行测试。 具体的流程如下面的流程图
在2023年的年初,我、五一和Ego一起参加了SeeDao的工作坊,和SeeDao一起实现了一个基于SeeDao notion数据的新人引导机器人,并拿到了二等奖。 至此我们走上了AI应用的开发和学习的道路。下面是我和我的团队在这半年里面一起完成的关于AI应用相关的内容。
关于大模型的一些基本概念可以看这个链接: AI应用技术的分享
在这半年中我尝试了各类大模型,包括文字、图像和语音。以下将从这几个方面介绍我对这些大模型的认知以及我和我的团队基于这些大模型实现的应用。
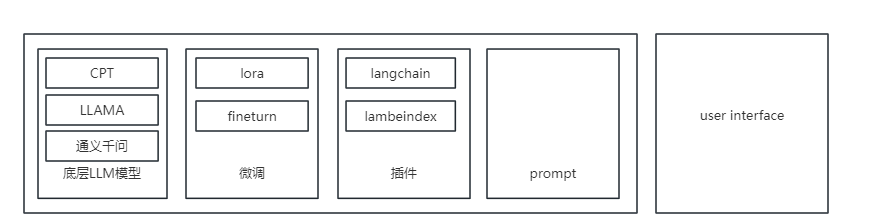
以语言大模型应用做为例子,往往一个AI应用包含以下的层
 istrat
istrat
底层大模型 主要负责推理
微调 是可选项
插件和prompt,主要负责功能的特异化,桥接大模型和用户。
底层大模型主要是国内外开源的模型,一般具有API,可以输入文本或者图像(如果模型支持多模态)数据,模型进行推理,输出文字或者图像。
后台向量数据存储部分包含的几个功能
登录模块包含三个主要功能,用户登录、用户注册、用户信息展示和修改 其他辅助的功能有保存用户登录状态,根据用户信息(角色)展示不同主页 用户角色当前有三种:
用户登录的流程
DiscordBot项目的目标是实现一个可以定制化配置的问答机器人,同时机器人具有特定领域的交互能力。
DiscordBot项目当前由以下4个模块组成
这四个模块之间的交互如下
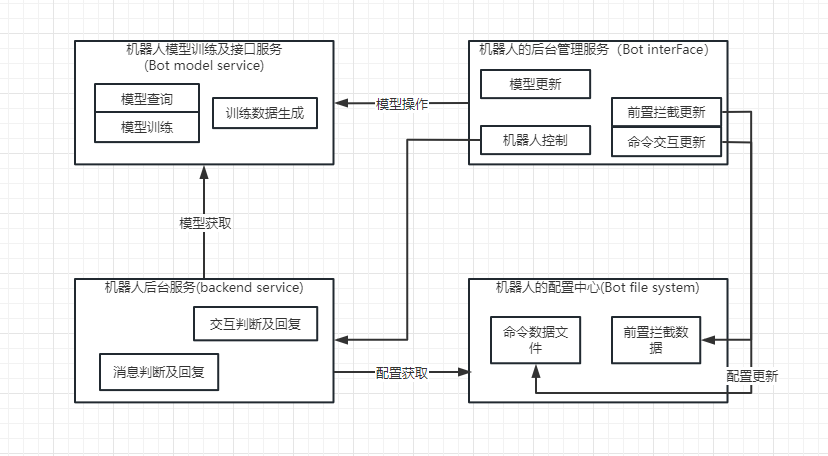
当Client产生一条消息后或产生一个交互,Discord GateWay将拦截到该消息或者交互,并将该消息通知到后端服务器
当后端接收到一个交互时
当后端收到消息时
将根据消息类型判断
如果是机器人产生的消息,丢弃
如果是@机器人的,将进行强制回复,将进行以下逻辑
判断是否包含头级关键词,如果不包含,将调用seeDaoAi接口回复
包含头级关键词则进行二级关键词判断,如果不包含二级关键词,将调用seeDaoAi接口回复
包含二级关键词,则进行三级关键词判断,如果不包含三级关键词,将调用seeDaoAi接口回复
包含三级关键词,则根据关键词寻找数据库内容进行结果返回。
如果是正常的消息,则进行以下的逻辑
判断是否为问句,如果不是问句,则不进行回复
判断是否包含头级关键词,如果不包含,则不进行回复
判断是否包含二级关键词,如果不包含,则不进行回复
判断是否包含三级关键词,如果不包含,则调用seeDaoAi接口回复
如果包含三级关键是,则数据库定位进行回复。
本项目实现一个自主回答和具有一定命令功能的AI机器人,用于实现seeDao在Discord社区的问题解答,以及对新人Onboarding的支持。 具体的架构图如下:
整个系统由3个模块组成,分别是