FreeBe开发和测试协作的方式探讨
前两天Zoe跟我聊了一下,关于FreeBe项目开发上的一些现状,由于前端和后端都是由一位或者两位作者在更新和维护,项目更新和维护的进度很难把控, 同时群里有很多技术方面的小伙伴也想参与到项目的开发和维护中,所以就当前基于github托管模式,提一些便于团队协作的建议。
具体的实现可以通过会议讨论去定义,以下内容可以作为参考
多分支及权限设置
大约 3 分钟

前两天Zoe跟我聊了一下,关于FreeBe项目开发上的一些现状,由于前端和后端都是由一位或者两位作者在更新和维护,项目更新和维护的进度很难把控, 同时群里有很多技术方面的小伙伴也想参与到项目的开发和维护中,所以就当前基于github托管模式,提一些便于团队协作的建议。
具体的实现可以通过会议讨论去定义,以下内容可以作为参考
 艾因,一个从C++到java,前端到后端,CICD到测试都沾点的全栈工程师。
艾因,一个从C++到java,前端到后端,CICD到测试都沾点的全栈工程师。
这里有一些标签,可以方便你首次认识我:
为了方便开发、测试和运维,这边建议采用两套服务器搭建开发环境和测试环境,采用GitHub作为代码托管,SonarCloud进行代码质量控制,DockerHub作为镜像托管,Git Action作为流水线控制,腾讯云作为服务器。 这样每次开发完成代码更新,测试链接就可以实时展示更新后的产品,方便demo展示和进行测试。 具体的流程如下面的流程图
图是一系列点集合和一系列边集合的二元组
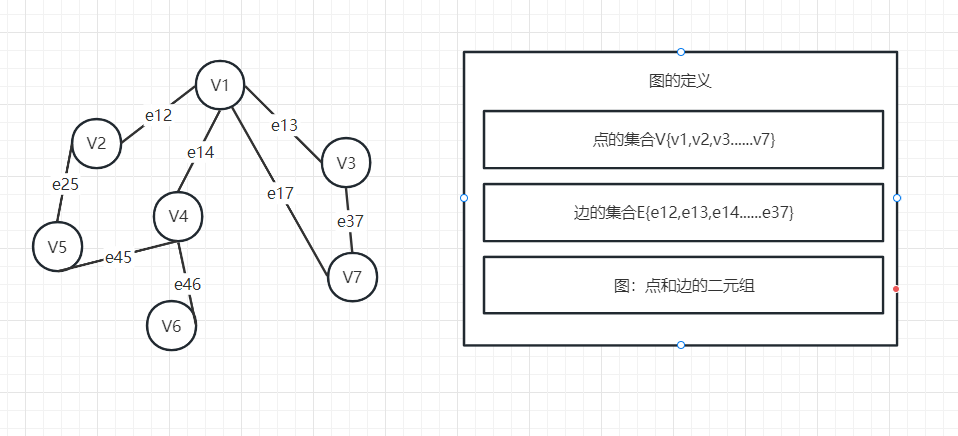
根据边是否有向,可以分成有向图和无向图,同时根据边是否带权,可以分成有权图和无权图。 所以一般的图可以分成四类,分别是无向无权图、有向无权图、无向有权图、有向有权图。
在2023年的年初,我、五一和Ego一起参加了SeeDao的工作坊,和SeeDao一起实现了一个基于SeeDao notion数据的新人引导机器人,并拿到了二等奖。 至此我们走上了AI应用的开发和学习的道路。下面是我和我的团队在这半年里面一起完成的关于AI应用相关的内容。
关于大模型的一些基本概念可以看这个链接: AI应用技术的分享
在这半年中我尝试了各类大模型,包括文字、图像和语音。以下将从这几个方面介绍我对这些大模型的认知以及我和我的团队基于这些大模型实现的应用。
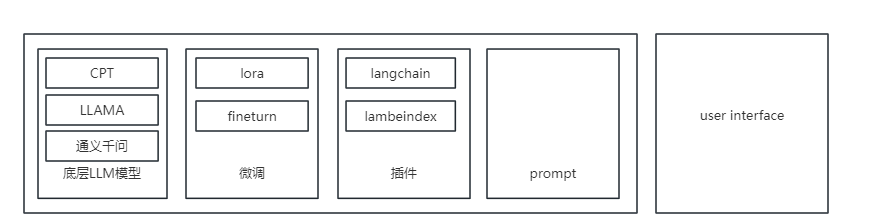
以语言大模型应用做为例子,往往一个AI应用包含以下的层
 istrat
istrat
底层大模型 主要负责推理
微调 是可选项
插件和prompt,主要负责功能的特异化,桥接大模型和用户。
底层大模型主要是国内外开源的模型,一般具有API,可以输入文本或者图像(如果模型支持多模态)数据,模型进行推理,输出文字或者图像。
后台向量数据存储部分包含的几个功能